
TemPredict: A Big Data Analytical Platform for Scalable Exploration and Monitoring of Personalized Multimodal Data for COVID-19
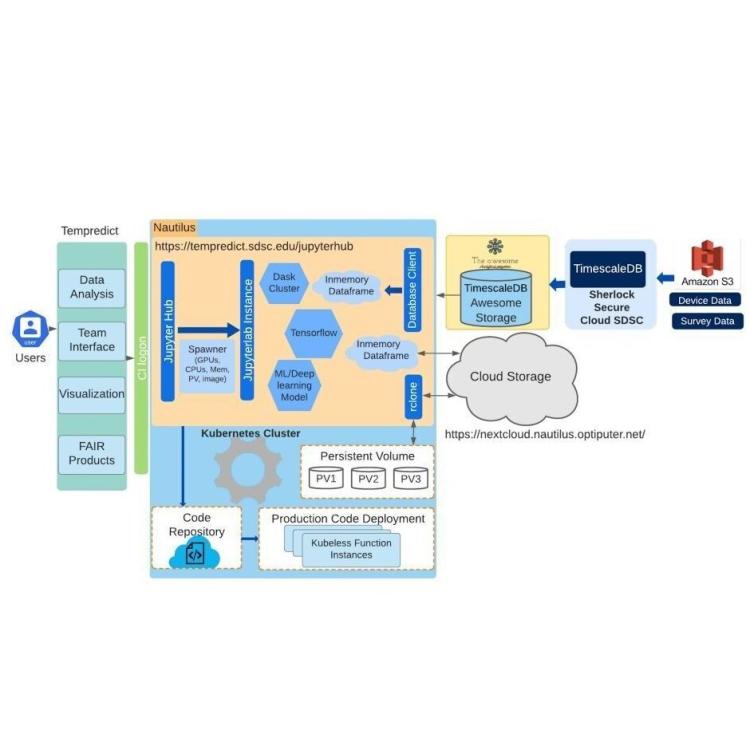
A key takeaway from the COVID-19 crisis is the need for scalable methods and systems for ingestion of big data related to the disease, such as models of the virus, health surveys, and social data, and the ability to integrate and analyze the ingested data rapidly. One specific example is the use of the Internet of Things and wearables (i.e., the Oura ring) to collect large-scale individualized data (e.g., temperature and heart rate) continuously and to create personalized baselines for detection of disease symptoms. Individualized data, when collected, has great potential to be linked with other datasets making it possible to combine individual and societal scale models for further understanding the disease. However, the volume and variability of such data require novel big data approaches to be developed as infrastructure for scalable use. This paper presents the data pipeline and big data infrastructure for the TemPredict project, which, to the best of our knowledge, is the largest public effort to gather continuous physiological data for time-series analysis. This effort unifies data ingestion with the development of a novel end-to-end cyberinfrastructure to enable the curation, cleaning, alignment, sketching, and passing of the data, in a secure manner, by the researchers making use of the ingested data for their COVID-19 detection algorithm development efforts. We present the challenges, the closed-loop data pipelines, and the secure infrastructure to support the development of time-sensitive algorithms for alerting individuals based on physiological predictors illness, enabling early intervention.


{kind=link}