Biomedical Big Data Training Collaborative (BBDTC): An Effort to Bridge the Talent Gap in Biomedical Science and Research
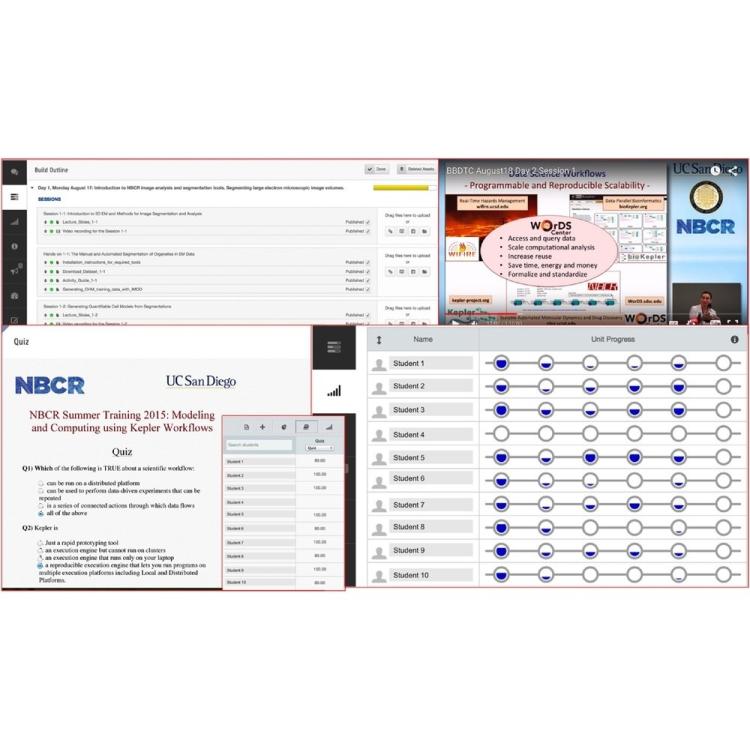
The BBDTC (https://biobigdata.ucsd.edu) is a community-oriented platform to encourage high-quality knowledge dissemination with the aim of growing a well-informed biomedical big data community through collaborative efforts on training and education. The BBDTC is an e-learning platform that empowers the biomedical community to develop, launch and share open training materials. It deploys hands-on software training toolboxes through virtualization technologies such as Amazon EC2 and Virtualbox. The BBDTC facilitates migration of courses across other course management platforms.